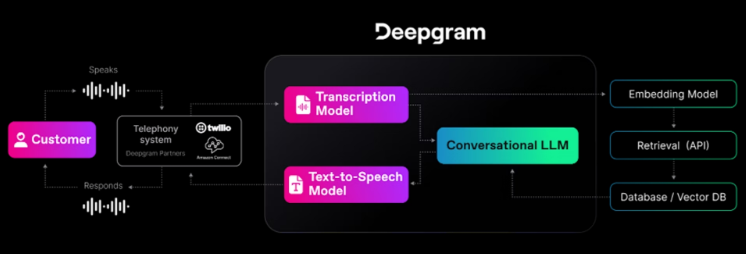
Hallo: 通过语音驱动头像动画生成
项目概述
Hallo是一个由复旦大学牵头的项目,旨在通过语音输入生成逼真的头像动画。这个项目联合了百度、苏黎世联邦理工学院和南京大学的研究力量,推动了这一技术的发展。
项目背景
近年来,利用语音驱动头像动画的技术取得了显著进展。这个项目探讨了如何在生成连续、逼真的动画时同步面部运动的复杂性。
创新点
- 端到端方法:与传统方法不同,这个项目采用了一种直接从语音生成动画的端到端方法,不需要中间的面部参数模型。
- 分层音频驱动:引入了分层音频驱动的视觉合成模块,可以更精确地对齐音频和视觉输出,包括嘴唇、表情和姿势的变化。
- 综合网络架构:该架构结合了生成模型、去噪技术、时间对齐技术和参考网络。
- 个性化控制:可以根据不同人物的特点调整表情和姿势,实现个性化的动画生成。
主要功能
虚拟角色动画:可以生成高质量的虚拟角色动画。
真实角色动画:支持生成逼真的真人头像动画。
动作控制:包括对姿势、表情和嘴唇运动的精确控制。
唱歌动画:生成与语音同步的唱歌动画。
跨角色动画:支持不同角色之间的动画切换。
项目成果
通过详细的测试和评估,这个方法在图像和视频质量、嘴唇同步精度和运动多样性方面都有显著提升。
总结
Hallo项目通过一个新颖的方法实现了语音驱动的头像动画生成。这种方法能够精确地同步音频和视觉效果,生成的动画逼真而多样化。无论是虚拟角色、真实人物还是唱歌动画,都能实现高质量的输出,并且可以在不同角色之间灵活切换。这项技术显著提升了图像和视频的质量及嘴唇同步的精度,为个性化动画制作提供了新的可能性。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。