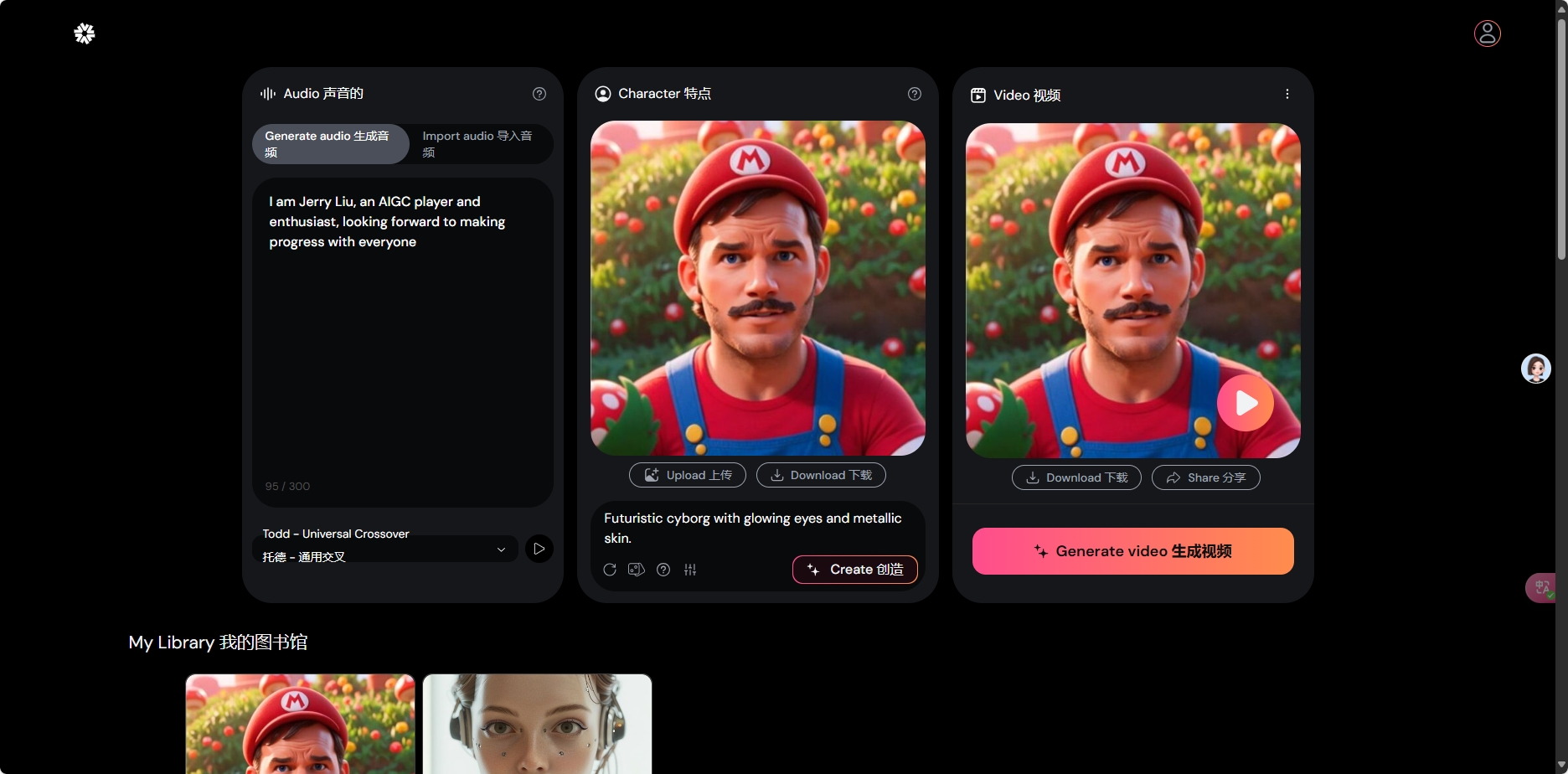
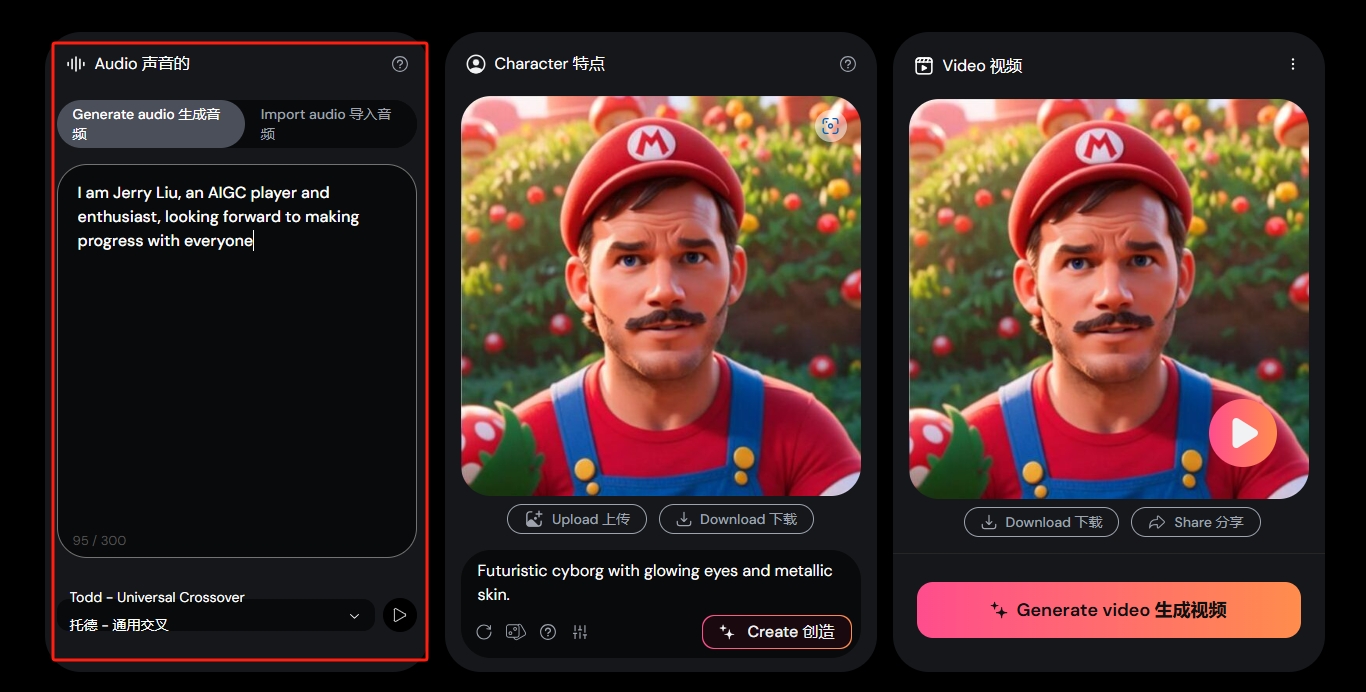
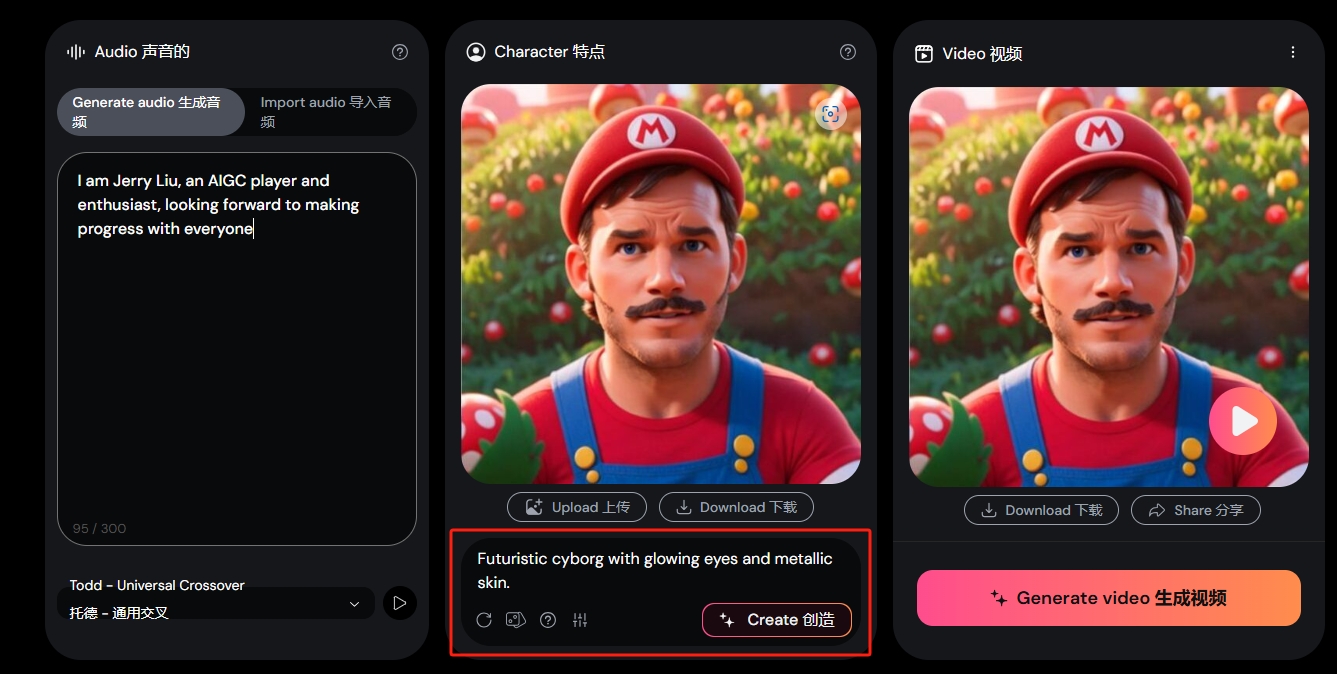
Hedra:上传人物照片+任意语音 可实现人物唱歌、说话
技术概述
Hedra Labs推出的Character-1是一款能够根据任意人物照片和语音内容生成个人会说话和唱歌的动态视频的工具。用户可以上传照片和语音文件,生成生动的动画视频。
主要功能
- 上传人物照片:
- 用户可以上传任意人物的照片,Hedra的AI技术能够识别并处理这些图像。

- 用户可以上传任意人物的照片,Hedra的AI技术能够识别并处理这些图像。
- 添加语音:
- 用户可以上传任何语音文件,Hedra的系统将语音与人物照片结合,实现人物说话或唱歌的效果。
- 生成生动的视频:
- Character-1可以生成具有表现力和可控人类角色的视频,保持唇形和表情、姿态与语音内容相一致。
- Character-1可以生成具有表现力和可控人类角色的视频,保持唇形和表情、姿态与语音内容相一致。
- 易于使用:
- 界面友好,用户无需专业技能即可轻松上手。
- 高质量输出:
- 通过先进的AI技术,生成高质量、逼真的视频内容。
使用方法
- 访问:Hedra官网
- 文字转语音:
- 输入或粘贴文本并选择一个预设的声音。
- 输入或粘贴文本并选择一个预设的声音。
- 上传音频:
- 输入角色描述,Hedra会生成角色。
- 输入角色描述,Hedra会生成角色。
- 生成视频:
- 满意后按“生成”按钮。
案例展示
- 表达性对话:
- 模型能够生成表现不同情绪的角色视频。
- 歌唱和说唱:
- 角色可以唱歌和说唱,保持高度一致性。
- 非人类角色:
- 生成表现丰富的无生命物体视频。
- 生成表现丰富的无生命物体视频。
未来发展方向
- 提升输出质量:
- 改进生成视频的画质和声音同步。
- 丰富功能:
- 增加更多的预设声音和个性化调整选项。
- 扩展应用场景:
- 应用于教育、娱乐和商业领域。
官网地址:荣誉 — Hedra
- 应用于教育、娱乐和商业领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。