
EchoMimic:通过音频和面部标志生成逼真的音画同步肖像视频

主要内容总结
项目简介
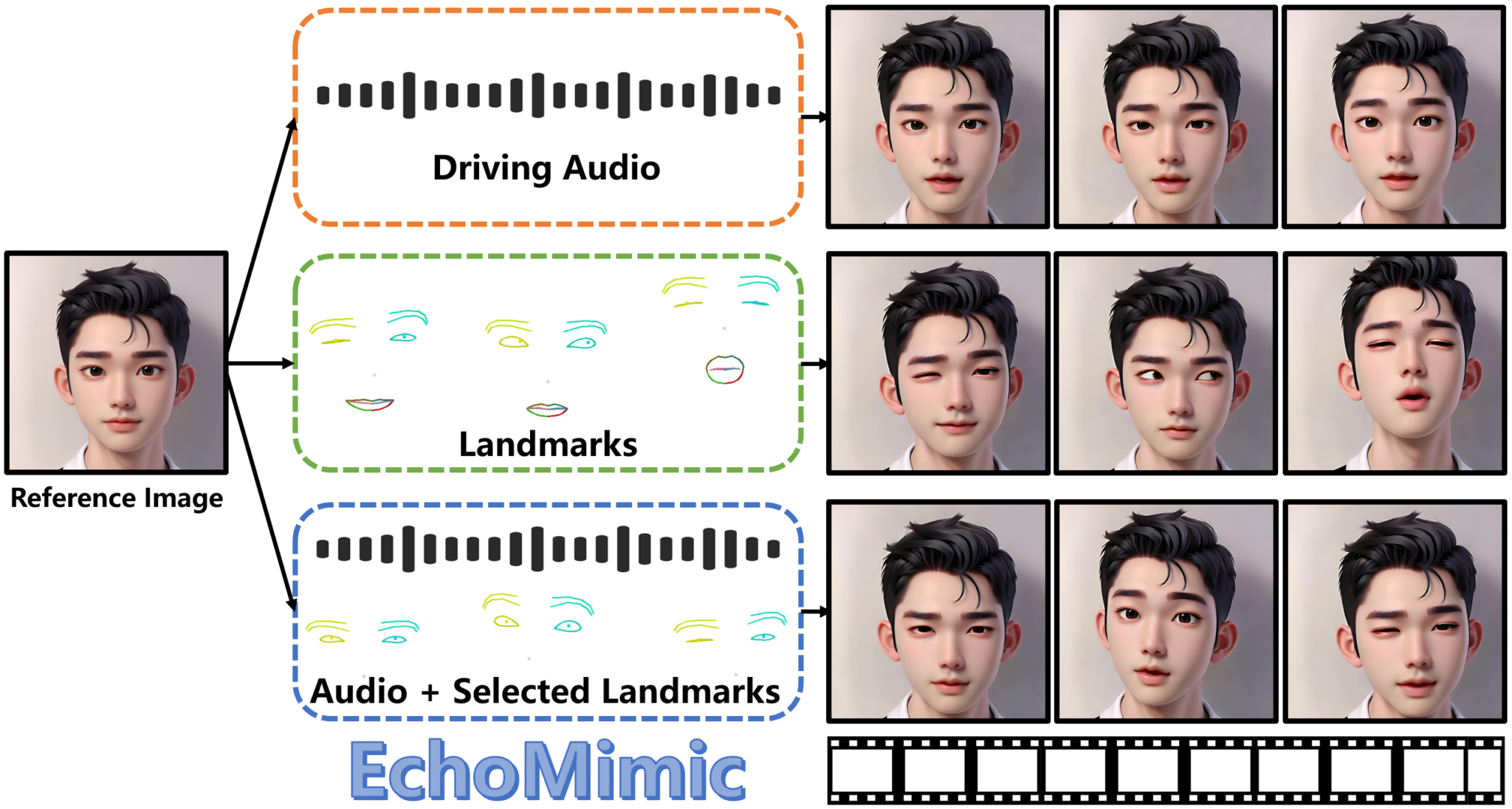
EchoMimic 是蚂蚁集团开发的一种新方法,用于通过音频和面部标志生成逼真的肖像动画视频。不同于传统方法,EchoMimic 可以结合音频和面部标志,提高生成视频的稳定性和自然度。
解决的问题
- 仅由音频驱动的不稳定性:传统方法仅使用音频信号,导致生成视频不稳定。EchoMimic 通过结合音频和面部标志,提高了视频的稳定性,使输出更加平滑和一致。
- 仅由面部关键点驱动的不自然性:传统方法仅使用面部关键点,生成结果往往显得不自然。EchoMimic 平衡音频和面部标志输入,使生成的视频更符合实际面部运动和表情变化。
效果与优势
- 稳定性:结合音频和面部标志,减少抖动和失真。
- 自然度:生成的面部动画更符合自然的面部运动和表情变化。
- 性能:在各种公共数据集和自有数据集上的表现优于现有方法。
面部标志点的介绍
面部标志点是指在面部图像上标注的一组特定点,用于表示面部的关键特征和结构,广泛应用于人脸识别、表情识别、面部动画等领域。
EchoMimic的主要功能
- 单独通过音频生成肖像视频:分析音频信号生成与音频同步的面部动画。
- 单独通过面部标志生成肖像视频:跟踪和使用面部标志的位置变化生成动画。
- 结合音频和面部标志生成肖像视频:核心功能是结合音频信号和面部标志位置变化,生成更自然逼真的肖像动画。
- 多语言和多风格支持:支持不同语言和风格的音频输入,如普通话、英语和歌唱等。
应用场景
- 面部识别:通过标志点的位置和形状识别人脸身份。
- 表情识别:分析标志点的变化识别面部表情和情感。
- 面部动画:驱动虚拟角色的面部动画,模仿真人表情和动作。
- 增强现实(AR):在面部标志点的位置叠加虚拟元素。
医学成像:用于面部结构分析和手术规划。
项目地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。