清华推出短视频AI理解新技术video-SALMONN:像人一样刷视频
摘要
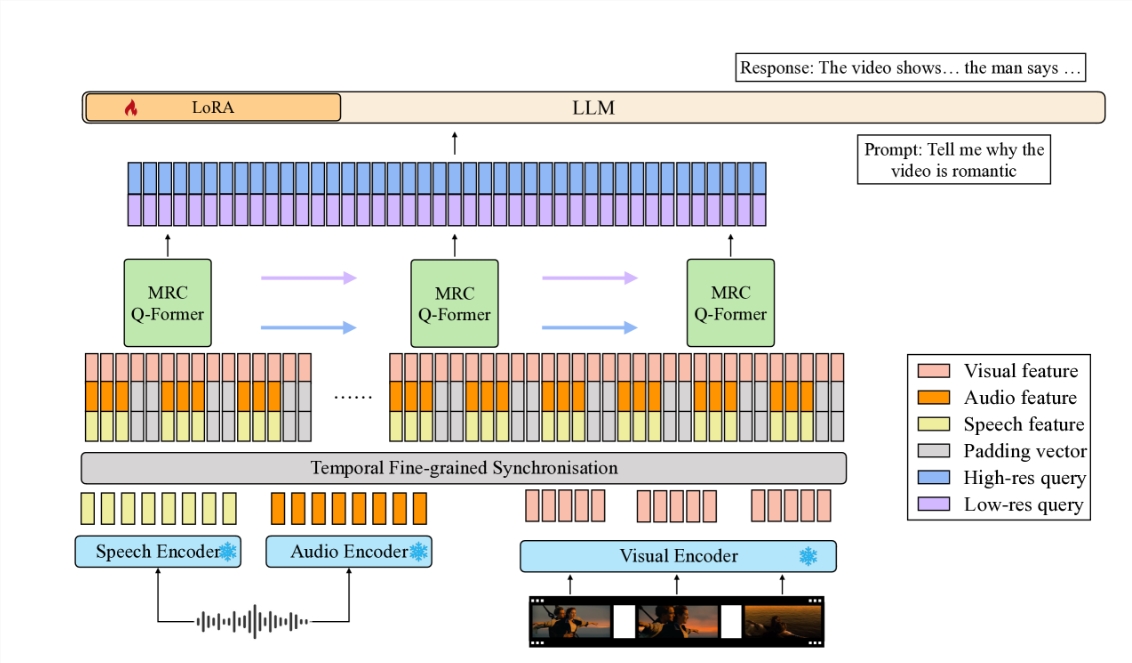
清华大学联合新加坡国立大学团队提出了一项名为video-SALMONN的新技术。这项技术能够理解视频中的视觉帧序列、音频事件、音乐和语音内容,标志着在机器理解视频内容方面的重大进展。video-SALMONN使用多分辨率因果Q-Former结构,将预训练的音视频编码器与大型语言模型连接,确保对视频元素的高效处理和细粒度时间信息的捕捉。在新的语音-音频-视觉评估基准(SAVE)上,该技术在视频问答和音视频问答任务上取得了显著的准确率提升。
主要特点
- 多分辨率因果Q-Former结构:实现对音视频输入特征与文本表示空间的对齐。
- 高效处理:捕捉细粒度时间信息,确保对视频元素的高效处理。
- 显著准确率提升:在视频问答和音视频问答任务上表现优异。
技术优势
- 时间因果关系增强:采用特殊因果掩码的因果自注意力结构,增强连续视频帧之间的时间因果关系。
- 多样性损失和未配对音视频混合训练:提高模型对不同视频元素的平衡处理。
- 广泛应用前景:为视频内容分析、教育应用和生活质量提升带来深远影响。
应用场景
- 视频内容分析
- 教育应用
- 生活质量提升
相关链接
– 论文地址
© 版权声明
文章版权归作者所有,未经允许请勿转载。