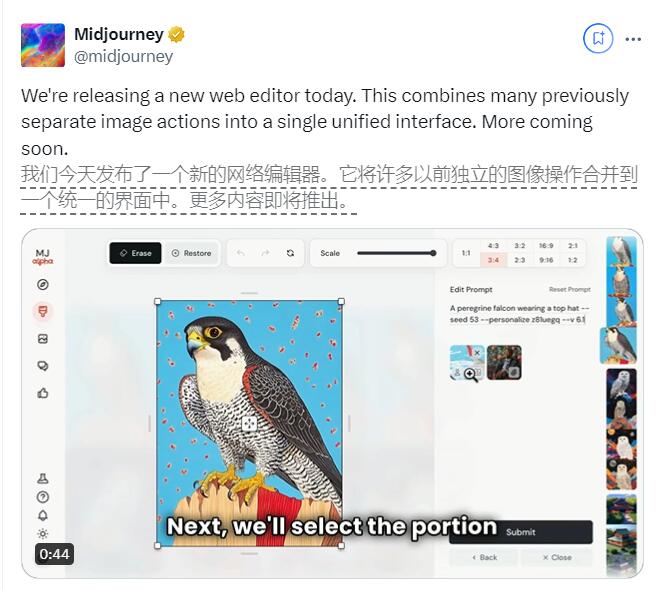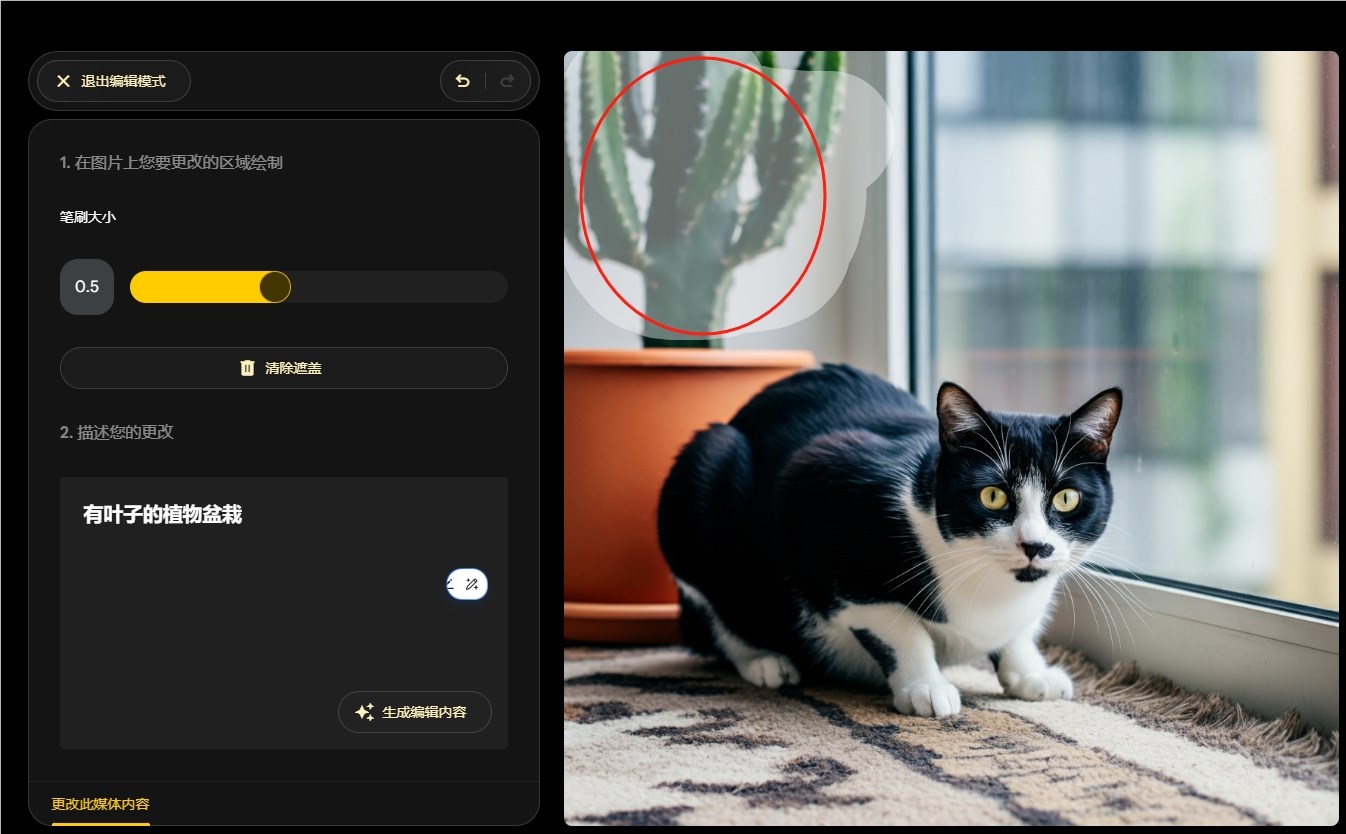
字节跳动推出Seed-ASR:先进的多语言自动语音识别模型
摘要
字节跳动开发了Seed-ASR,一种高级的自动语音识别(ASR)模型,基于大语言模型(LLM)框架构建,专门处理多语言、方言和口音的语音信号。该模型在普通话和13种中国方言,以及英语等8种语言上表现卓越,并计划扩展至超过40种语言。
主要特点
- 📈 高识别准确率:大规模训练显著降低字错误率(WER)。
- 🔊 大模型容量:配备近20亿参数的音频编码器和专家混合大语言模型。
- 🌐 多语言支持:支持普通话、方言及多国语言识别。
- 💬 上下文感知能力:利用对话历史等上下文信息提高准确性。
技术优势
- 🛠️ 分阶段训练流程:自监督学习到强化学习逐步优化性能。
- 📱 无需额外语言模型的部署能力:简化部署流程,降低系统复杂性。
- 🔍 长语音内容处理:无需分段,直接处理长时间语音输入。
应用场景
- 🎤 会议记录和日常对话转录。
- 🎬 视频和直播内容的语音识别。
- 🔎 语音搜索和智能助手交互。
评估结果
Seed-ASR 在多个测试集上展现出色性能,尤其在中文和英文识别任务中,错误率大幅降低。
相关链接
– 项目及演示
– 研究论文
© 版权声明
文章版权归作者所有,未经允许请勿转载。