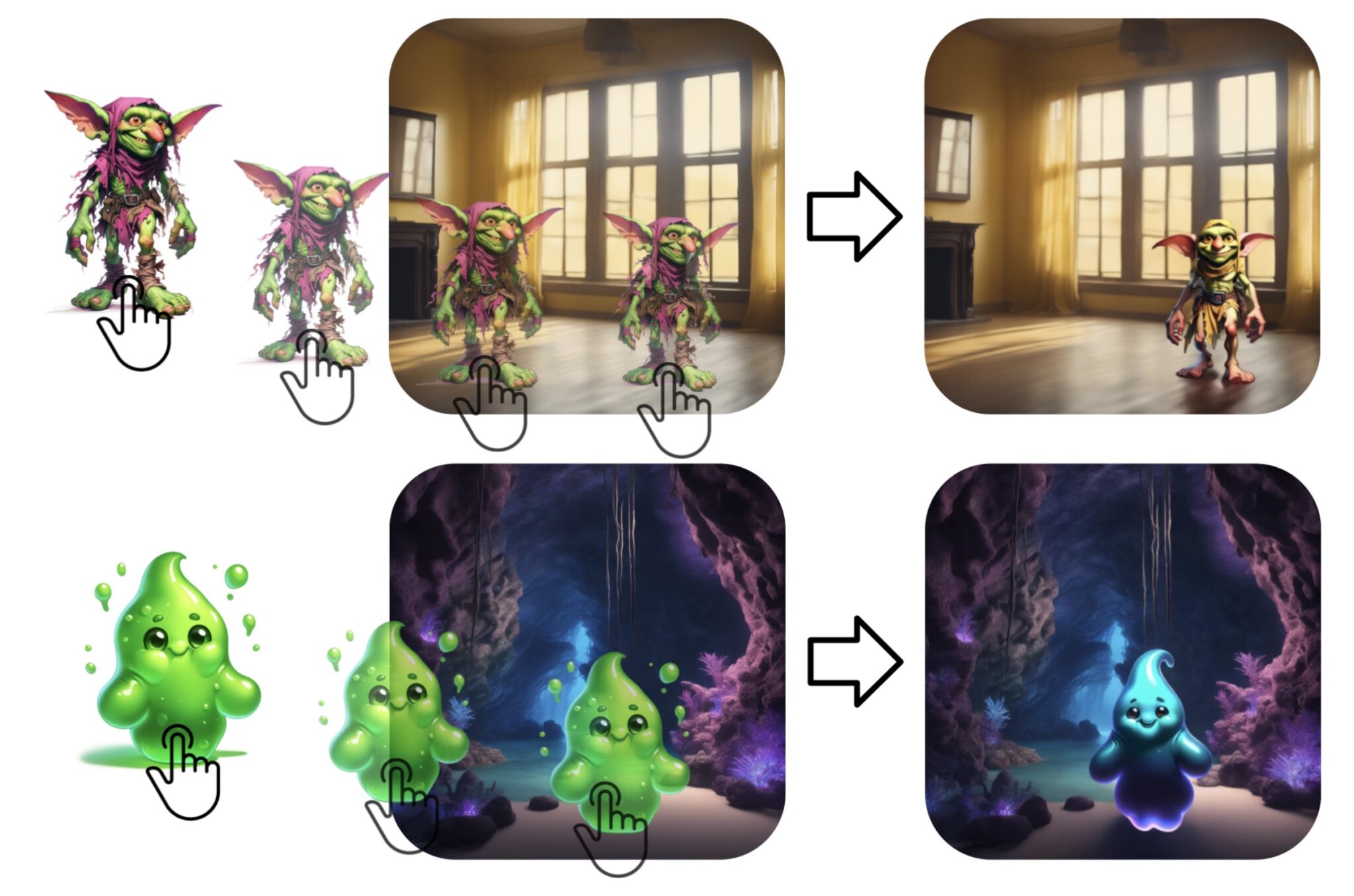
创新AI技术:Magic Insert实现图像元素风格融合 Magic Insert:将一个图像中的人或物体拖放到另一个风格图像中 并实现风格融合 摘要 Magic Insert 是一项创新的 AI 技术,可以将一个图像中的人或物体拖放到另一个风格图像中,并实... 小野资讯 1年前5,4300
OpenAI开发新AI模型“Strawberry”,提升自主推理和互联网浏览能力 OpenAI开发新AI模型“Strawberry”,提升自主推理和互联网浏览能力 摘要 据路透社报道,OpenAI 正在开发一个代号为“Strawberry”的新人工智能模型项目。该项目旨在通过增强推... 小野资讯 1年前5,4600
谷歌开天眼:Gemini 1.5 Pro赋予机器人记忆导航超能力 谷歌开天眼:Gemini 1.5 Pro赋予机器人记忆导航超能力 摘要 Google DeepMind 推出了一个名为 Gemini 1.5 Pro 的系统,并将其安装在机器人上,使其具备记忆导航能力... 小野资讯 1年前5,5500
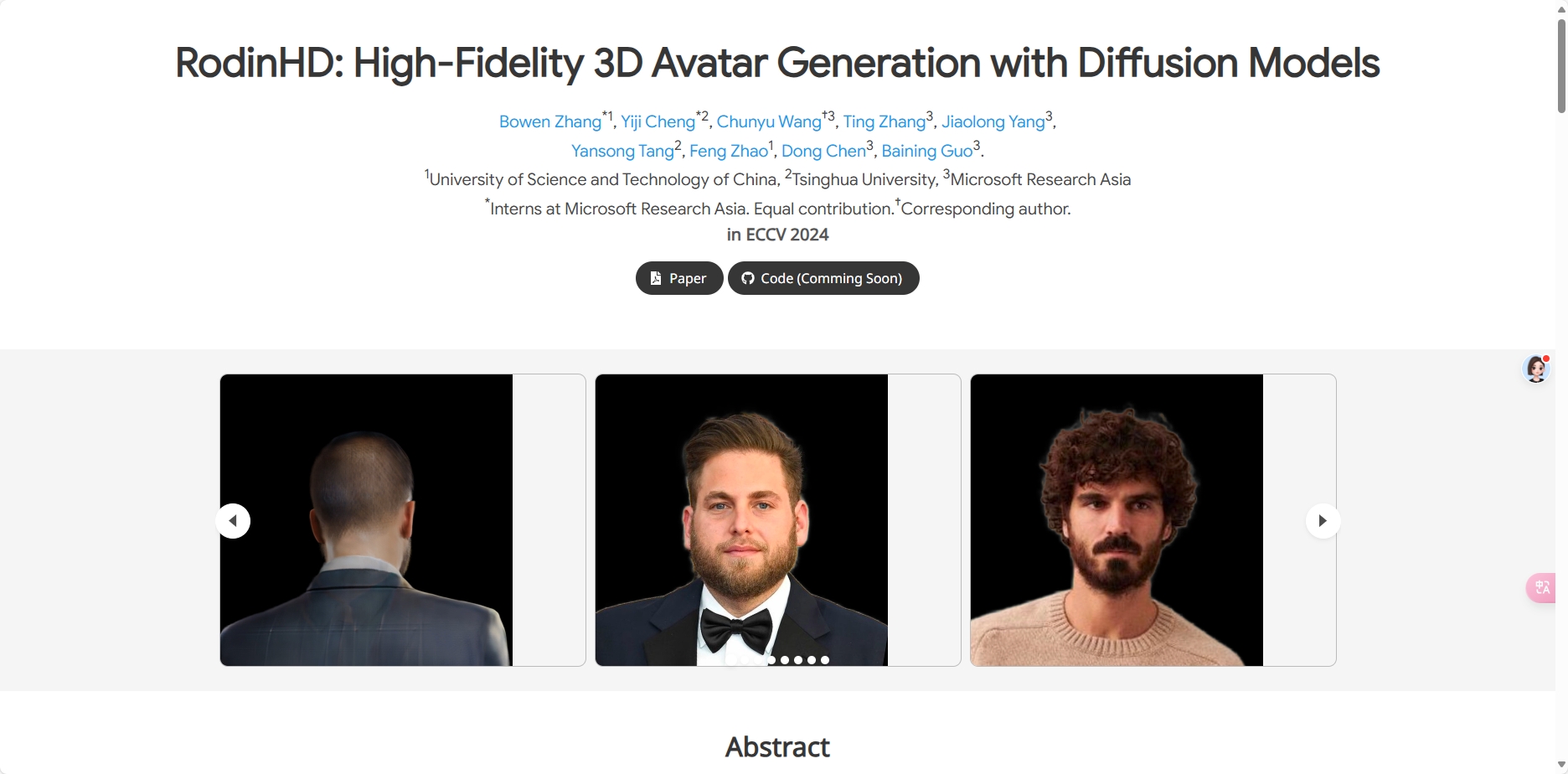
RodinHD:可根据肖像生成高保真3D头像模型,头发细节也有了 RodinHD:可根据肖像生成高保真3D头像模型,头发细节也有了 摘要 RodinHD 技术能够将肖像照片转化为高保真的3D头像模型,包括细致的头发细节。核心在于创新的三平面拟合与生成框架,通过高分辨... 小野资讯 1年前7,0100
国产开源绘画模型 Kolors:支持中文字符,质量超越 SD3 和 MidJourney 国产开源绘画模型 Kolors:支持中文字符,质量超越 SD3 和 MidJourney 摘要 快手公司推出了「可图 Kolors」开源绘画模型,基于潜在扩散的大规模文本到图像生成技术。Kolors ... 小野资讯 1年前6,2100
Midjourney v6.5 将于7月底发布,带来更真实的图像体验 Midjourney v6.5 将于7月底发布,带来更真实的图像体验 Midjourney,作为人工智能图像生成领域的佼佼者,计划在本月底发布其6.5版本。这次更新将显著提升图像的真实感和皮肤纹理,为... 小野资讯 1年前4,7600
Heygen推出全新AI对口型工具:上传照片和音频即可生成说话视频 Heygen推出全新AI对口型工具:上传照片和音频即可生成说话视频 最近,AI照片“复活术”在网络上引起了广泛关注。Heygen推出了一款对口型工具,用户只需上传一张照片和一段音频,照片中的人物即可根... 小野资讯 1年前22,8400
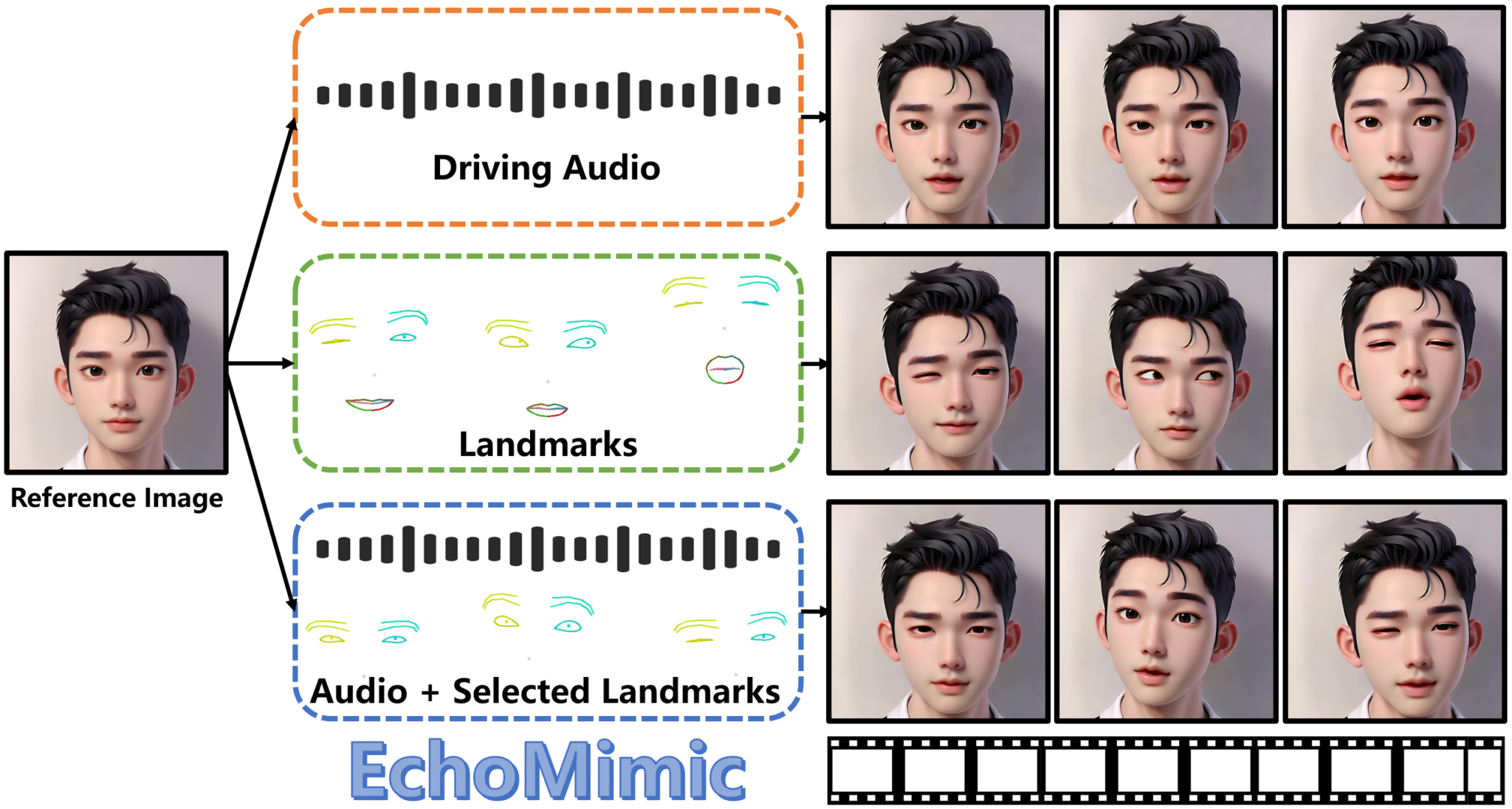
EchoMimic:通过音频和面部标志生成逼真的音画同步肖像视频 EchoMimic:通过音频和面部标志生成逼真的音画同步肖像视频 主要内容总结 项目简介 EchoMimic 是蚂蚁集团开发的一种新方法,用于通过音频和面部标志生成逼真的肖像动画视频。不同于传统方法... 小野资讯 1年前14,5000
PaintsUndo:输入静态图像 自动帮你生成整个绘画的全过程视频 PaintsUndo:输入静态图像 自动帮你生成整个绘画的全过程视频 专业总结 PaintsUndo 是一个旨在模拟数字绘画行为的基础模型。用户通过输入静态图像,该模型可以自动生成一个展示绘画全过程的... 小野资讯 1年前14,0300
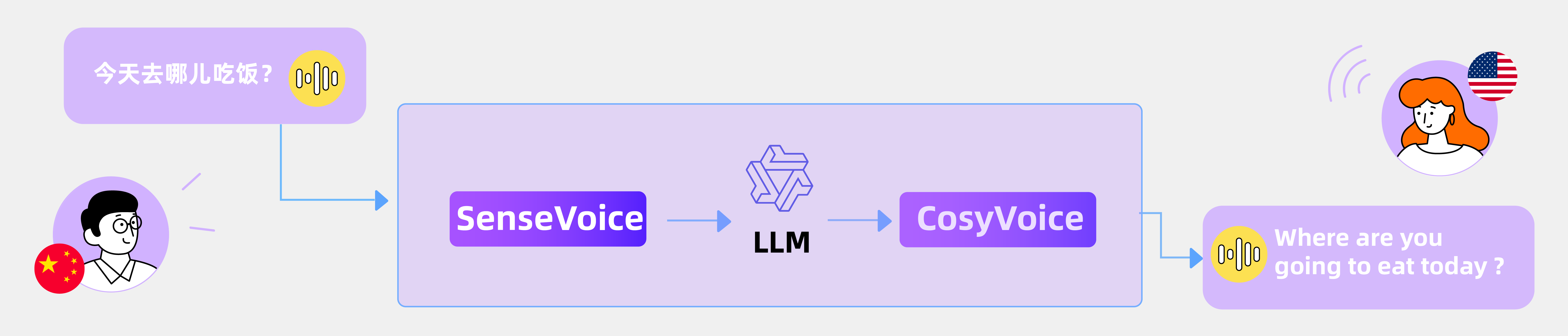
阿里巴巴发布语音处理模型 FunAudioLLM 能理解和生成各种人类语音 阿里巴巴发布语音处理模型 FunAudioLLM 能理解和生成各种人类语音 专业总结 阿里巴巴开发的 FunAudioLLM 是一组先进的语音处理模型,旨在提升人类与大语言模型之间的语音交互体验。它由... 小野资讯 1年前6,7300